
BigQueryは多種多様なビッグデータの格納やインポート処理、分析が可能なGoogleのデータウェアハウスサービスです。
本ページでは、ローカル環境にあるファイルからBigQueryのテーブルにロードする3つの方法を紹介します。
ローカルにあるファイルをBigQueryのテーブルとして読み込むには、
- Cloud Console
bqコマンドラインツール- BigQuery API
を利用する3つの方法が存在します。
Cloud Console
ブラウザでGCPにアクセスしてプロジェクトを作成し、BigQueryにデータセット、テーブルを作成する方法です。すべてGCPのWeb UI画面上で設定しながら進めることができます。
実際にローカルPCにあるファイルをアップロードしてBigQueryのテーブルを作成してみます。
ファイルはヘッダ付きのCSV形式で、以下のような10,000件のレコードから成る注文データです。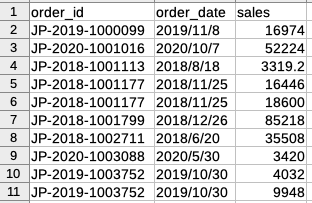
まず最初にCloud Consoleにアクセスして、プロジェクトを選択します。
プロジェクトが未作成の場合は、「新しいプロジェクト」をクリックして作成します。
プロジェクト名を入力して「作成」をクリックします。
次にBigQueryを起動して、データセットを作成します。
プロジェクトの右端をクリックして「データセットを作成」を選択します。
データセットIDとデータのロケーションを入力して「データセットを作成」をクリックします。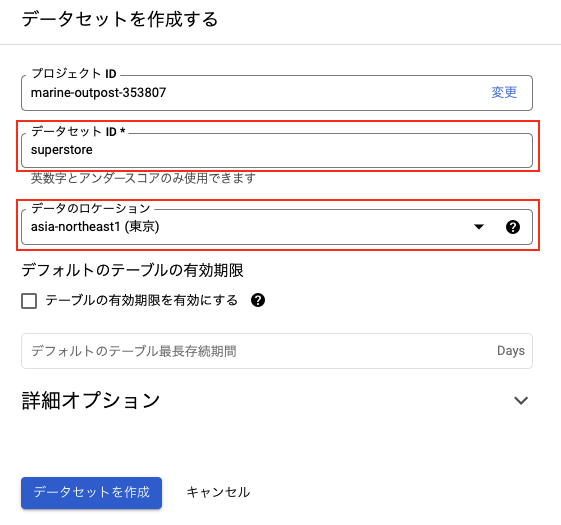
さらにテーブルを作成します。
データセットの右端をクリックして「テーブルを作成」を選択します。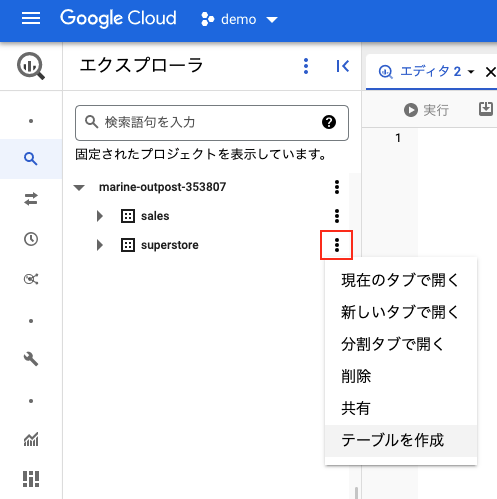
テーブルの作成元は「アップロード」、ファイルを選択、ファイル形式を「csv」に設定、テーブル名を入力して、スキーマの「自動検出」にチェックを入れます。自動検出をオンにすると、BigQueryがデータの型を推定して設定してくれます。設定後に手動で変更することもできます。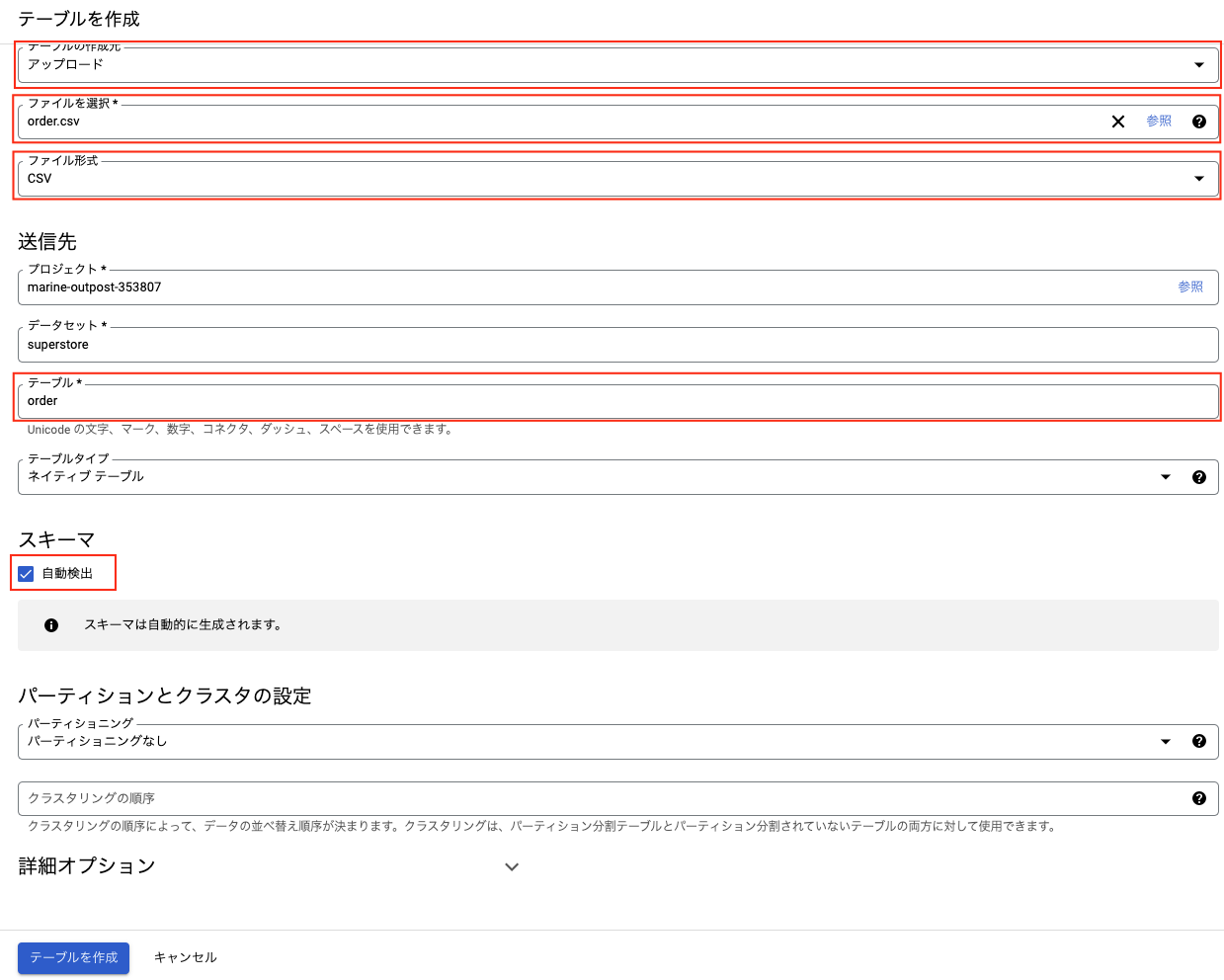
テーブルが作成されました。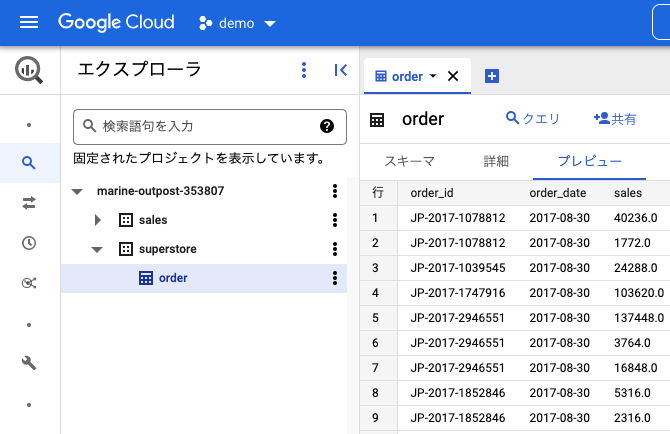
bqコマンドライン
Googleから提供されているBigQueryを操作するコマンドラインツール「bqコマンド」を利用する方法です。
GCPのCloud Shellのターミナルを立ち上げると、インストール不要ですぐにbqコマンドを利用できます。
実際に以下のbqコマンドを利用して、ローカルにあるファイルを読み込んでみたいと思います。
bq ls # データセットの表示
bq show # テーブルの表示
bq mk # データセット、テーブルなどの作成
bq load # データの読み込みまず最初にCloud Consoleにアクセスして、プロジェクトを選択します。
(プロジェクトが未作成の場合は新規に作成します。)
次に右上のアイコンをクリックして、Cloud Shellを起動します。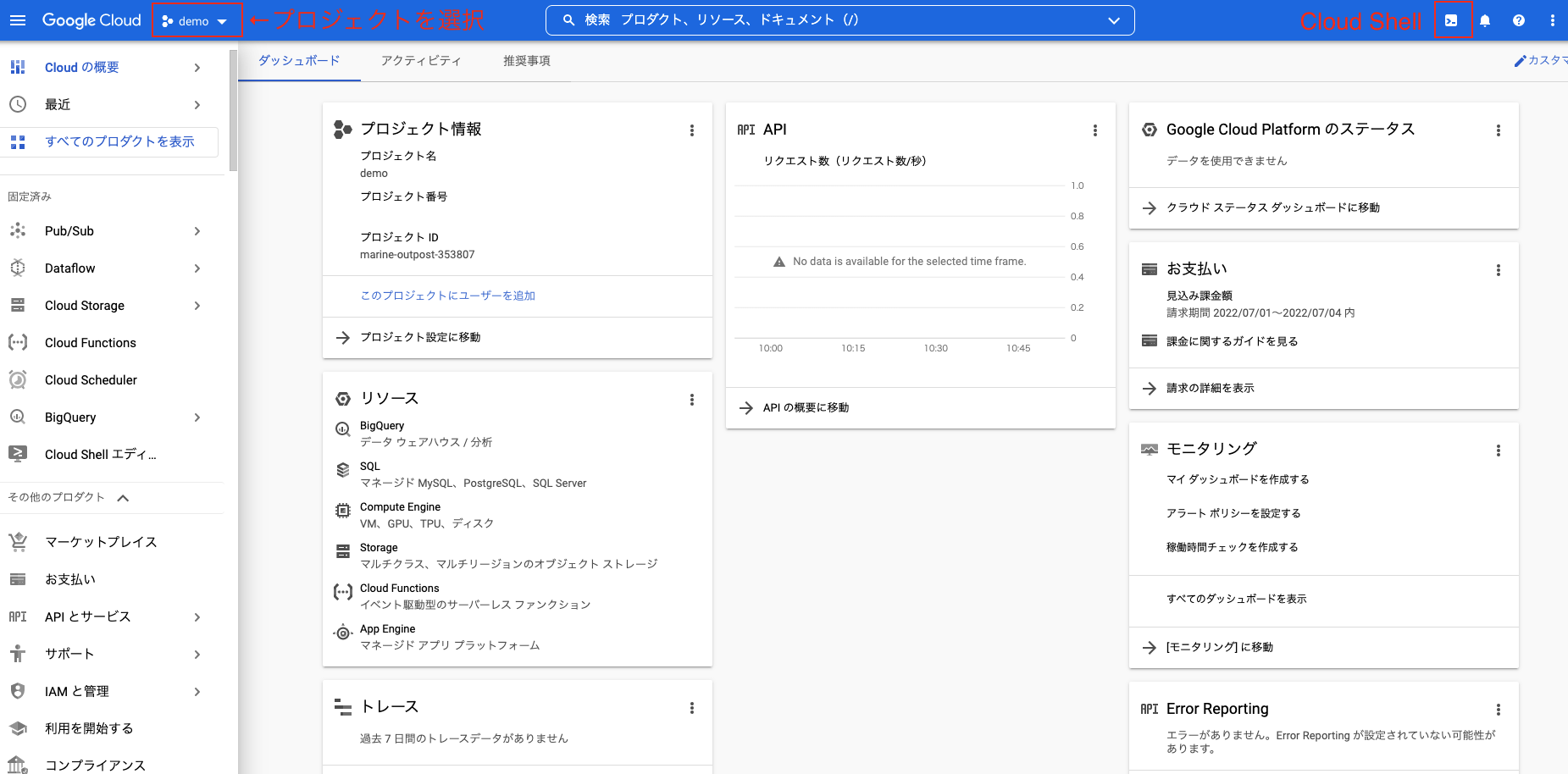
以下のような画面が立ち上がります。
シェルが起動できたら、ローカルのファイルをGCPにアップします。
画面右上の3ドットをクリックして、リストから「アップロード」を選択します。
編集画面でファイルを選択してアップロードします。
今回はcsvファイルをアップします。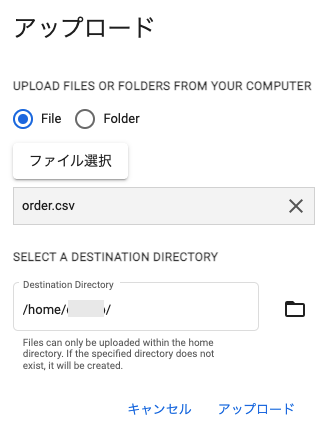

以下のようにアップされたことが確認できます。![]()
アップできたので、いよいよbqコマンドを利用してBigQueryにロードします。
データセット「superstore」を作成します。
アップしたファイル「order.csv」をテーブル「superstore.order」にスキーマを定義してロードします。
失敗しました。。。
エラー内容を見てみると、csvファイルのヘッダーで躓いているようなので、スキーマを定義せずに自動検出オプション(--autodetect)を指定して再度実行してみます。
今度はできました。
テーブルとスキーマを確認してみます。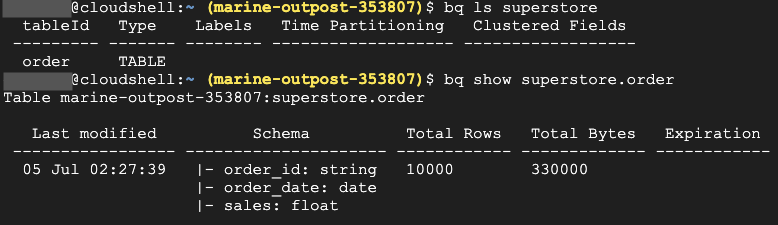
BigQueryを開いて、作成されていることが確認できます。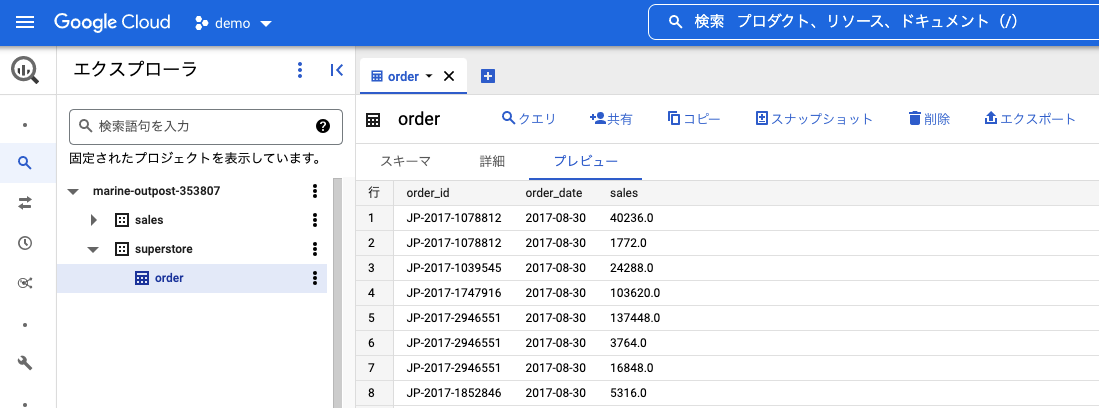
BigQuery API(python)
Googleから提供されているBigQuery APIを利用して、コードからファイルをロードする方法です。
GCPのCloud Shellを利用すれば、APIパッケージがインストール済みなので、すぐにエディタでコードを作成してターミナルで実行することができます。
ここではpythonを例に、実際にローカルにあるファイルを読み込んでみたいと思います。
まず最初にCloud Consoleにアクセスして、プロジェクトを選択します。
(プロジェクトが未作成の場合は新規に作成します。)
次に右上のアイコンをクリックして、Cloud Shellを起動します。
以下のような画面が立ち上がります。
続いて画面右上の「エディタを開く」をクリックして、エディタを起動します。
エディタでpythonのコードを作成します。
メニューの「File」をクリックして、リストから「New File」を選択します。
以下のようなpythonのコードを作成します。
メニューの「File」をクリックして、リストから「Save as」を選択、名前を付けて保存します。
今回は「load_file2bq.py」で保存しました。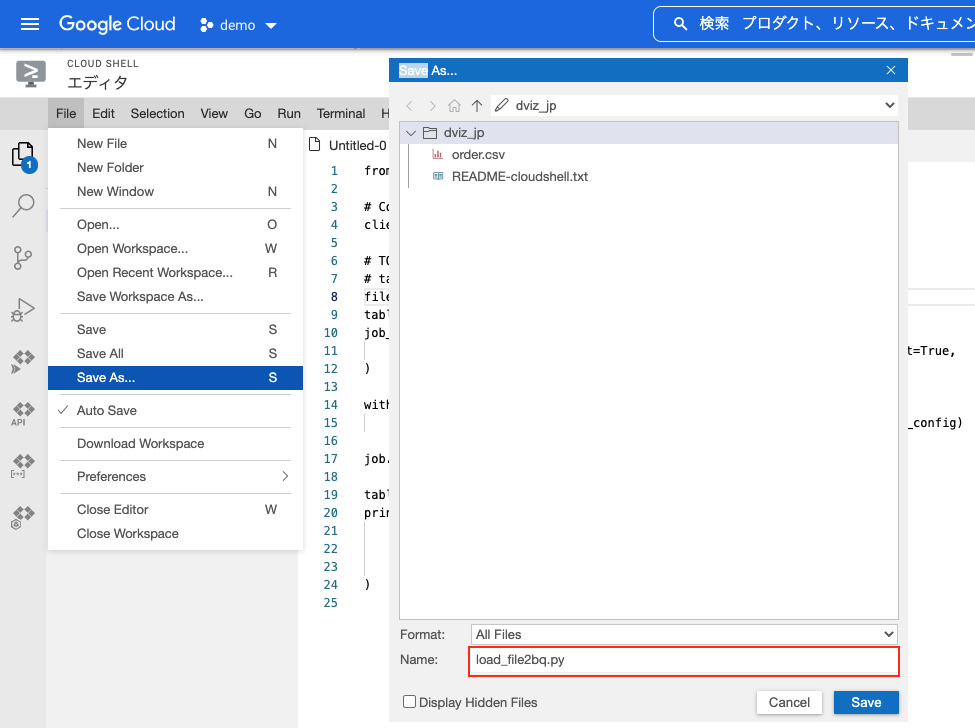
画面右上の「ターミナルを開く」をクリックして、再びターミナルに切り替えます。
pythonのファイルを実行します。![]()
BigQueryを開いて、作成されていることが確認できます。
本ページでは、ローカル環境にあるファイルからBigQueryのテーブルにロードする3つの方法を紹介しました。

今回は自動検出していますが、以下のようにスキーマを定義して先頭1行をスキップして読み込む指定も可能です。
csvデータ読み込みの際に指定可能なオプションは色々あります。
詳細は以下のGoogleのサイトに掲載されています。
なお現時点では、bqコマンドでローカルの複数ファイルをロードする場合はサポートされておらず、ファイルは個別にロードする必要があるようです。複数ファイルをロードしたい場合には、Cloud Storageにファイルを置いて一括処理することができます。