
Tableauでは様々な計算が関数として標準で用意されているので、それらを利用して集計をすることができます。
本ページではTableauの文字列関数の中からよく利用するCONTAINS、FIND、LEFT、REPLACE、SPLIT、TRIM関数を紹介します。
CONTAINS
CONTAINS関数はある文字列に特定の文字列が含まれているかどうかを判定する関数で、次のように記述します。
CONTAINS(string, substring)
文字列stringに特定の文字列substringが含まれている場合はtrueを返します。
スーパーストアのデータを利用した例をみてみましょう。
出荷モードが「通常配送」の注文を調べてみましょう。
出荷モードが文字列「通常」を含むかどうかを判定する計算式を作成します。
計算結果を確認してみましょう。
データペインの「オーダーId」、「出荷モード」、作成した計算式を行にドラッグ&ドロップします。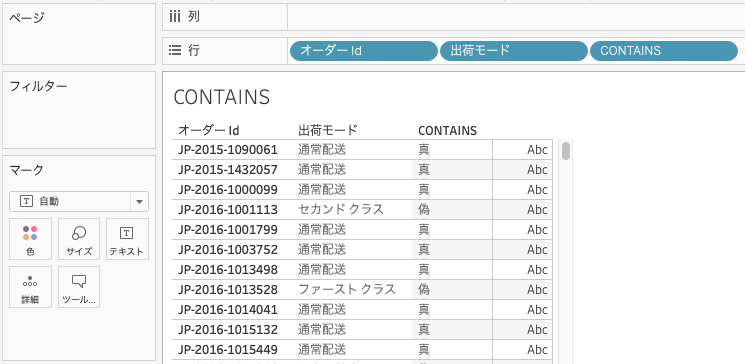
出荷モードが「通常配送」の場合はCONTINS関数が真を返し、それ以外の場合には偽を返していることが分かります。
YouTubeでも紹介しています。(0:15〜)
FIND
FIND関数はある文字列にマッチする特定の文字列の位置を返す関数です。
FIND(string, substring, [start])
文字列stringの先頭から検索を開始して最初に特定の文字列substringにマッチする位置を返します。substringが見つからない場合は、0を返します。
オプションの引数startを指定した場合は、startの位置から検索を開始します。
スーパーストアのデータを利用した例をみてみましょう。
オーダーidから最初のハイフンの位置を集計してみましょう。
オーダーidの文字列の先頭から最初にハイフンが出現する位置を求める計算式を作成します。
計算結果を確認してみましょう。
データペインの「オーダーId」を行、作成した計算式をマークのテキストにドラッグ&ドロップします。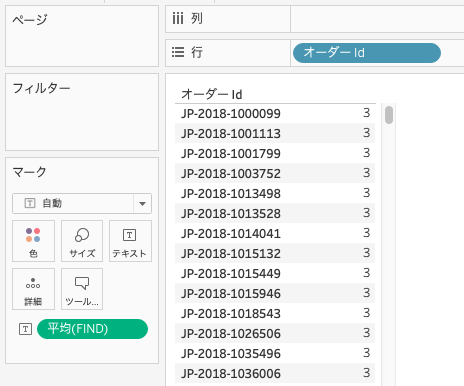
オーダーidでの文字列は3文字目にハイフンが出現していることが分かります。
YouTubeでも紹介しています。(1:48〜FIND、3:22〜FINDNTH)
LEFT
LEFT関数は文字列の先頭の文字列を抽出する関数で次のように定義します。
LEFT(string, number)
文字列stringの先頭からnumber分の文字列を返します。
スーパーストアのデータを利用した例をみてみましょう。
オーダーidから最初のハイフンより前の文字を取り出してみましょう。
オーダーidの文字列の先頭から最初にハイフンが出現する位置までを取り出す計算式を作成します。
計算結果を確認してみましょう。
データペインの「オーダーId」を行、作成した計算式をマークのテキストにドラッグ&ドロップします。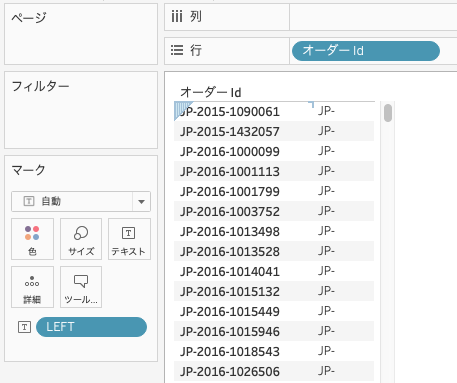
オーダーidでの文字列で、1文字目から最初にハイフンが出現する3文字目までの文字列「JP-」が返されていることが分かります。
LEFT関数とは逆に末尾の文字列を抽出するRIGHTという関数も存在します。
YouTubeでも紹介しています。(2:38〜LEFT、4:58〜RIGHT)
REPLACE
REPLACE関数は文字列の一部を別の文字列に置き変える関数で次のように記述します。
REPLACE(string, substring, replacement)
文字列stringの先頭から検索を開始して特定の文字列substringがマッチしたら文字列replacementで置き換えます。substringが見つからない場合には何もしません。
スーパーストアのデータを利用した例をみてみましょう。
オーダーIdの国番号「JP」を「JPN」に置換してみましょう。
オーダーIdのJPを置換する計算式を作成します。
計算結果を確認してみましょう。
データペインの「オーダーId」を行、作成した計算式をマークのテキストにドラッグ&ドロップします。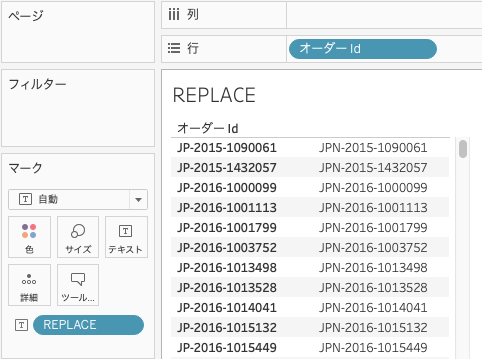
オーダーIdの国番号「JP」が「JPN」に変更されたことがわかります。
YouTubeでも紹介しています。(0:20〜)
SPLIT
SPILIT関数は文字列を分割する関数で次のように記述します。
SPLIT(string, delimiter, token number)
文字列stringを区切り文字列delimiterで分割し、token numberで指定された順番の文字列を返します。
token numberに正の整数を指定した場合には左から、負の整数を指定した場合には右からそれぞれカウントします。
スーパーストアのデータを利用した例をみてみましょう。
製品IdからIdのみを切り出してみましょう。
製品Idは「事務用-画材-10002175」のように「カテゴリ」「サブカテゴリ」「Id」の順にハイフンで接続された文字列なので、この特徴を利用して「Id」のみを取り出してみます。
製品Idをハイフンで区切り左から3目の文字列を取り出す計算式を作成します。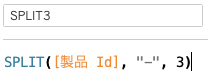
計算結果を確認してみましょう。
データペインの「製品Id」を行、作成した計算式をマークのテキストにドラッグ&ドロップします。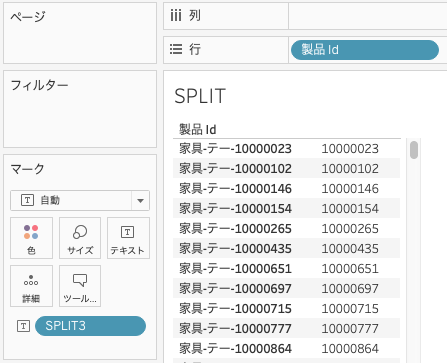
製品IdからId部分が抽出されていることが分かります。
token numberを「-1」に変更した以下の計算式でも同じ結果になります。
計算結果を確認してみましょう。
作成した計算式を置き換えてみます。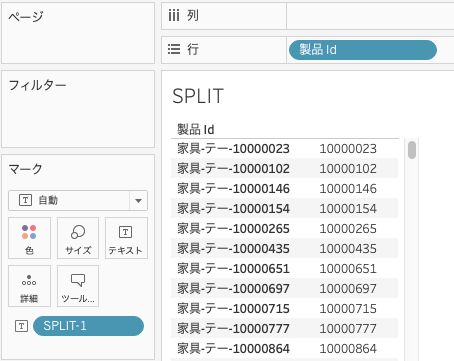
結果は変わらず、製品IdからId部分が抽出されていることが分かります。
YouTubeでも紹介しています。(3:47〜)
TRIM
TRIM関数は文字列の先頭と末尾の空白を削除する関数で次のように記述します。
TRIM(string)
文字列stringから先頭と末尾の空白を削除した文字列を返します。空白が見つからない場合には何もしません。
例えばTRIM(" JP-2016 1001113 ")とすると"JP-2016 1001113"が返ります。
空白は文字列の比較や他の処理にも影響を及ぼします。誤った集計や分析の原因になりがちなので、空白が入る可能性が疑われるフィールドには以下のようにTRIM関数を適用します。

TRIM関数の他にも、先頭の空白を削除するLTRIMや末尾の空白を削除するRTRIMもあります。
本ページではTableauの文字列関数の中からよく利用するCONTAINS、FIND、LEFT、REPLACE、SPLIT、TRIM関数を紹介しました。
